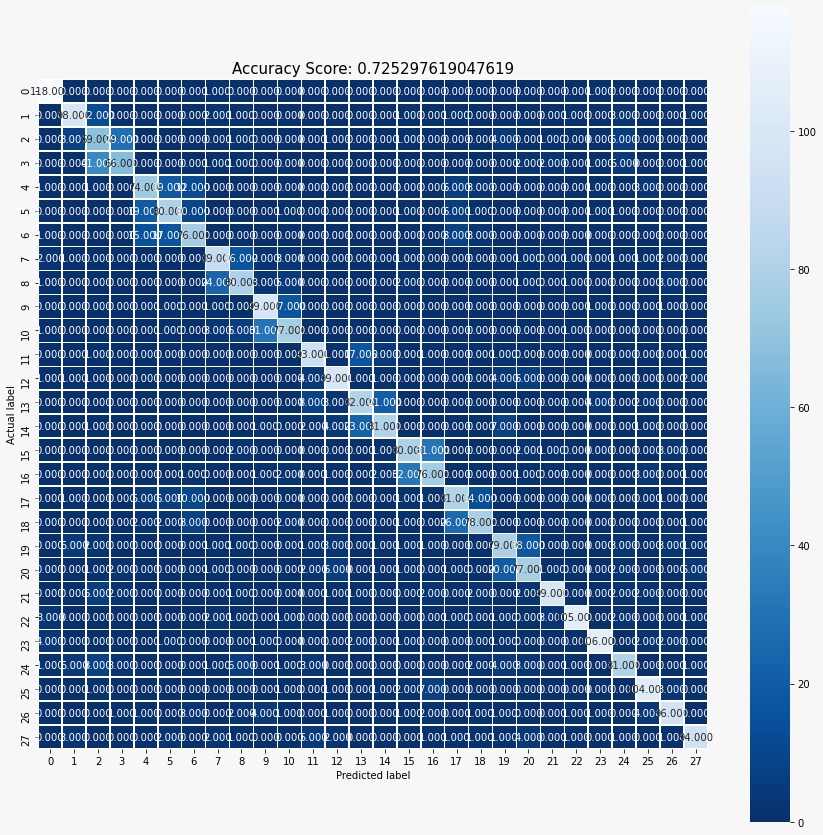
 Figure 1: Confusion Matrix of the Best Accuracy SVM Model.
Figure 1: Confusion Matrix of the Best Accuracy SVM Model.
For SVM, we used three types of kernels to train the data, which are linear kernel, the radial basis function (RBF) kernel and the sigmoid function kernel. The accuracy was acquired from testing set, where we adjusted our penalty parameter, C, for each run. The penalty parameter, C, of the error term was varied over the range from 0.0001 to 100. The best results were obtained with the RBF kernel SVM for C = 100 with test accuracy of 72.53%.
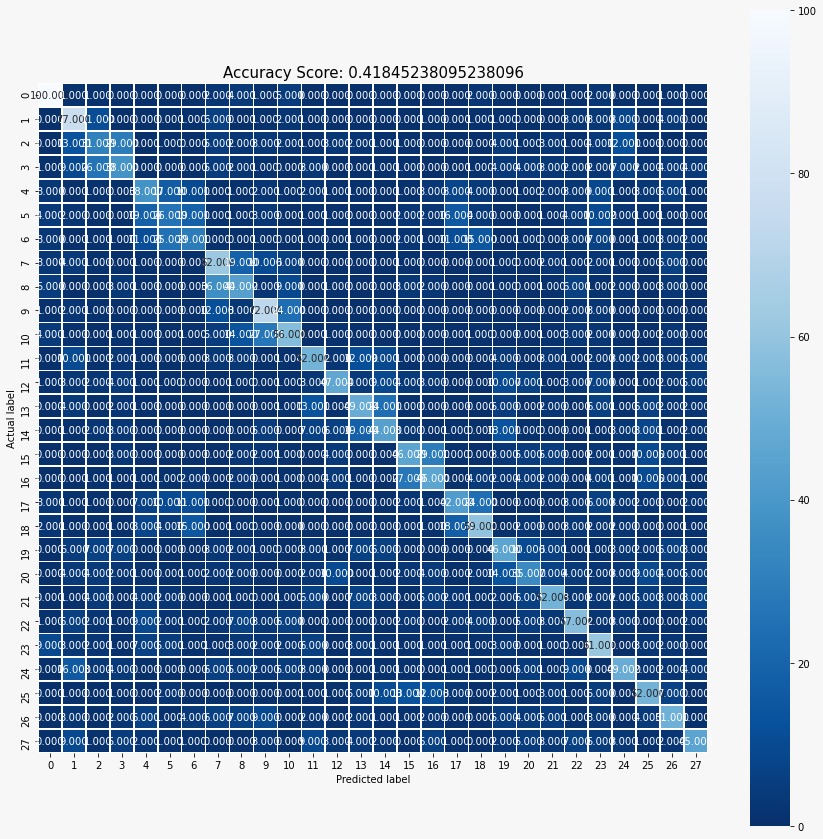 Figure 2: Confusion Matrix of the Best Accuracy Logistic Regression Model.
Figure 2: Confusion Matrix of the Best Accuracy Logistic Regression Model.
For Logistic Regression, we have used three data feature transformations - none, degree 2, and degree 3. The accuracy was acquired from testing set, where we adjusted our penalty parameter, C, for each run. The penalty parameter, C, of the error term was varied over the range from 0.0001 to 100. The best results were obtained with the no data transformation model for C = 0.1 with test accuracy of 41.85%.
 Figure 3: Confusion Matrix of the Best Accuracy Convolutional Neural Network Model.
Figure 3: Confusion Matrix of the Best Accuracy Convolutional Neural Network Model.
For CNN, we used four types of activation functions to train the data such as Linear, Leaky ReLU, Sigmoid and Tanh. Each time we trained our model 5 times (5 epochs). The best results were obtained by using Tanh activation function with a 91.63% of validation accuracy. Additionally, we analyzed how the alpha term affects the model’s accuracy when using Leaky ReLU activation function. After running the model, the final accuracy is equal to around 0.947 or 94.7%.